Upgrading Drupal 7 to Drupal 9: What to expect

As a Drupal 7 user or website owner, it’s important to understand what’s next for your web presence as Drupal 7 and Drupal 8 reach their respective end-of-life. While learning that your Drupal version will no longer be supported can seem scary, you’re certainly not alone in the upgrade process. Drupal users, administrators, and developers all over the world are migrating their websites to the latest version of Drupal.
At Redfin Solutions, we’ve helped nearly all of our clients complete major Drupal upgrades, from 7 to 8 and 7 to 9—and the rest of our clients have upgrades scheduled. This guide will help you understand what to expect so that you can plan accordingly and get a sense for the resources you’ll need to allocate to upgrade Drupal 7 to 9.
Why upgrade Drupal 7 to Drupal 9
First things first: why is a Drupal 7 to 9 upgrade even necessary? In short, Drupal 7 will soon cease to be supported and upgrading to Drupal 9 will ensure your website uses the most secure Drupal code. It will also give you access to exciting new features such as the Layout Builder module for easily creating visual layouts with a drag-and-drop interface, out-of-the-box multilingual capabilities, and the ability to quickly make small content changes without navigating to the edit page.
Drupal 7 will reach its end-of-life in November 2023. Drupal 8 introduced a paradigm shift in configuration management, coding methodology, and theming (the way a website is styled). However, the differences between Drupal 8 and Drupal 9 are minimal. For this reason, the Drupal community originally recommended migrating incrementally from 7 to 8 and then 8 to 9. However, an extension of Drupal 7 support due to the Covid-19 pandemic shifted timelines around. Now, Drupal 8 is actually reaching its end-of-life before Drupal 7, on November 2nd, 2021. With this in mind, it makes sense for many Drupal 7 websites to upgrade directly to Drupal 9.
What is unique about this upgrade
Unlike past Drupal upgrades, a lot is changing when you go from 7 to 9. While these changes are widely seen as improvements for developers, content creators and end users alike, it means an upgrade from Drupal 7 to Drupal 9 could require more time and resources than other upgrades. To upgrade from Drupal 7 to any newer version of Drupal, a website needs to be almost entirely rebuilt — there is no upgrade “button,” unfortunately. Rather than porting over themes and custom modules, developers may have to write a lot of new code to get a site up and running on Drupal 9. But don’t worry—this doesn’t mean you’ll have to rewrite every blog post and staff bio! Most content can be migrated relatively seamlessly by an experienced Drupal developer.
Drupal upgrade considerations
To determine how large of a project your Drupal 7 to 9 upgrade will be, take some time to think about the following factors that are likely to affect project scope.
The size and complexity of your website
This one might seem like common sense: The larger and more complex your website is, the more resources will be needed to recreate it on Drupal 9. Determining the size of your website should be relatively simple. You can get a count of the number of nodes or pages your site contains by exporting pages from Drupal, consulting your XML sitemap, or using Google Search Console to see the number of pages crawled for tracking by Google. If you’re unfamiliar with administering your site, a developer can help you determine this by running reports that group the amount of content per type.
Determining the complexity of your site can be a bit more challenging, but it’s also likely to carry more weight in determining the scope of your upgrade. Generally speaking, the number of content types, taxonomies, views, modules, and custom fields your site uses will greatly affect the developer time needed for the upgrade. For instance, if your website has 15 content types, each with their own unique data fields and designs, a developer will need to recreate and then restyle each of those page templates. Some other complexities may include faceted search indices that allow users to apply filters to specific types of content, multilingual features, and custom modules or other custom code.
The Drupal modules you currently use
As mentioned in the last section, custom modules will require significantly more resources to upgrade than contributed or core Drupal modules. This is worth repeating because custom modules will need to be entirely rebuilt in the new Symfony framework (the back-end PHP framework that’s used in Drupal 8 and beyond) and because migrating the content in custom modules is itself a time consuming task that’s necessary to ensure no content is lost.
However, even “standard” Drupal 7 modules may not migrate seamlessly to Drupal 9. Modules that you currently use may not yet be supported on Drupal 9, or they may have been discontinued altogether in favor of newer modules that better conform to today’s best practices. If this is the case, time will be spent to determine what Drupal 9 modules can take their place.
Your required website integrations
Does your website have a reservation system that is connected to third party software? Perhaps you use a calendar integration or have data that maps directly to a CRM like Salesforce? Knowing what integrations your site needs to support, how flexible you’re willing to be with third-party software, and how customized your integrations are (i.e. is there an API module used “out of the box” or was custom code written to sync data from one platform to another?) will help you determine whether integrations will significantly affect the scope of your upgrade.
Your ideas for a refresh or redesign
With an upgrade from Drupal 7 to 9, a website rebuild is guaranteed. However, how many changes you make to your website at the time of the upgrade is up to you. Consider whether a website redesign or a refresh is appropriate for your brand and your budget.
Many companies and organizations use the upgrade as an opportunity to audit, refresh, or even entirely redesign their website. While incorporating a redesign likely means allocating more resources, it also means getting the most value for your time and money while you’re already “under the hood,” so to speak. Even if you don’t opt for a full redesign at the time of your upgrade, it’s a good idea to audit your site and determine if there are any outdated features, functionalities, or content that simply don’t need to be migrated or could be implemented more efficiently.
How to get started with your upgrade
The first step in any upgrade is to take stock of your current website. This should involve an audit of your modules, content, and important features. Next, you’ll want to start thinking about your roadmap for the future. For instance, is now the right time to consider a redesign? What organizational goals or plans may affect your upgrade timeline?
If you need help getting started with an audit or strategizing for the future of your site, get in touch with the Redfin Solutions team today to start planning your Drupal upgrade!
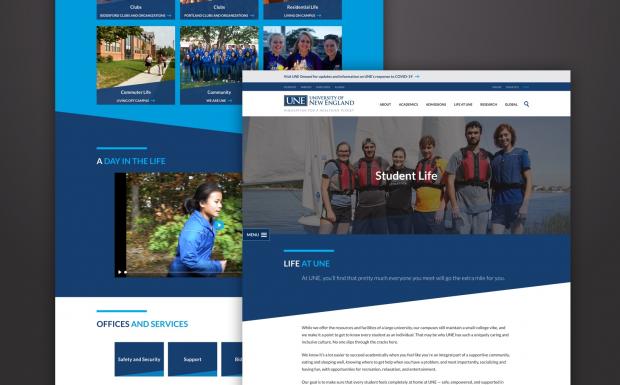
How to Find the Right Drupal Web Design Agency

Whether you’re launching a completely new Drupal website or it’s time to consider redesigning an outdated website, the prospect of finding the right web design agency can feel like a daunting process. However, to meet your business goals and users’ needs, choosing the right firm is an important step.
Drupal excels at providing an easy content authoring experience for complex websites. You’ll want to make the most of its scalability and flexibility by working with web designers and developers that understand Drupal design. Here are some key aspects to keep in mind when thinking about your Drupal design process, looking for a Drupal web design agency, and making sure you can recognize red flags.
What to know about Drupal design
It's not (quite) a blank slate for designers
It’s true that Drupal is highly flexible. You can customize almost everything on your Drupal website, from layouts and colors to content organization and integrations. However, it’s important to keep in mind that as a content management system (CMS), Drupal relies on some standard “building blocks” to allow for quick and consistent content authoring. Every Drupal website has a Theme, or a collection of files that define the presentation of your website. In addition to standard assets like CSS and Javascript files, some of these are Drupal-specific files. For instance, Drupal regions must be added to a theme to control where the content is displayed and how the page is marked up in HTML. It’s necessary for Drupal web designers to understand the basic mechanics of a Drupal website and understand how design concepts will translate into Drupal development.
Design is component based
If you’re following recognized best practices for scalable web design and development, you’ll want to think about your Drupal design in terms of components rather than just pages. In practice, component-based design (also called Atomic Design) means that designs are broken down into smaller component parts that can be combined and rearranged in a number of ways to create different page templates. For example, your smallest components may include buttons, labels, and input boxes. These components always look the same, but they can be re-used and rearranged to create search bars, sign-up forms, or calls to action. These elements can then be combined with others to create larger elements such as headers or modals.
While component-based design is popular across the web, it’s especially important for Drupal websites in order to take advantage of the flexibility and scalability Drupal offers while maintaining consistency and easy content authoring across a complex website. Drupal 8 has modules such as Layout Builder (included with the Drupal Core distribution) and Paragraphs that make implementing component-based design much easier than it’s been before.

Your information architecture matters
When you think of a website design, visual elements like colors, images, and typography probably come to mind. These visual components are undoubtedly important, but it’s likely that the information architecture underlying the visual design is just as important—if not more important—to helping users find content and maintaining an attractive, consistent, and user-friendly website. Some ways that information architecture is manifested include site maps, hierarchies and categorizations (i.e. taxonomies), navigation, and metadata.
Choosing the right Drupal web design agency
Now that you know the basics of what designing a Drupal website entails, how do you find the right agency for the job?
Look for Drupal design examples
Often, the most sure-fire way to see whether an agency has the Drupal design experience you’re looking for is to check out the other work they’ve done. Think about the different features of your web design project that are the highest priority or may be unique to your website and make sure the agency you hire has a track record of success on similar projects. For instance, if you’re redesigning a website for a university office, you may look for companies that have previously designed higher education websites. Or if your website needs a reservation system, check if the agency you choose has experience integrating websites with reservation software and constituent relationship manager (CRM)s. Of course, you’ll want to ensure the examples you see are from Drupal websites!
Ask about the design process
If you’re unsure about an agency’s design process or it’s not clear in their proposal, it’s more than okay to ask! The agency you choose should have an established “Discovery” phase devoted to understanding your business goals and your users. This might involve creating user personas or defining the key tasks you expect users to be able to accomplish on your website. You may also want to gain clarity about what design deliverables they’ll provide. Depending on the size and scope of your project, this might involve sitemaps, user journeys, wireframes, or design mocks, for instance. Most importantly, ensure that the design process is user-centered.
These days, it’s a good sign if an agency follows an agile approach to design—meaning work is conducted iteratively in two week increments called sprints. The Agile methodology allows stakeholders to provide more feedback and re-examine goals as the project moves along. You can also ask about how designers and developers at the agency work together. A good rapport and established workflow between designers and developers goes a long way toward ensuring your final product looks like the mocks a designer shows you.
Check out their involvement in the Drupal community
The best way to tell whether an agency has real Drupal credentials is to take a look at their involvement in the Drupal community. If they’ve contributed code to Drupal modules or have played a part in organizing Drupal events, it’s likely they’ve committed to keeping up with best practices for designing Drupal websites. At Redfin Solutions, for instance, we regularly sponsor Design 4 Drupal, Boston, an annual conference devoted to design, UX, and front-end development for Drupal websites.

Assess their communication style
Remember, you’re going to be working closely with the web design agency you choose. Beyond technical skills, it’s important that a web design agency prioritizes communication skills and customer service. Even the most genius tech wizards are only as good as their ability to communicate with you and listen. After all, it is your website.
Red flags: what to look out for
Don’t get caught off guard when it’s time to launch your website. Keep these red flags in mind when you’re choosing an agency to ensure a successful project.
Avoid designers who don't know Drupal
There are many great web designers out there that aren’t familiar with Drupal. You should avoid them if you’re building a Drupal website. This isn’t because their designs won’t look great on Drupal—it’s because there’s a good chance they won’t know how to implement them in a Drupal environment. This applies to any software or content management system. Choosing a web design agency that specializes in the platforms that your website uses will ensure you get the most out of the technology you’ve got.
Beware an inadequate discovery phase
In an attempt to provide you with the lowest quote possible, a design agency might nix or skimp on the discovery phase. But without this essential first step in the process, an agency can’t possibly build a user experience that delights your users and helps you achieve your business’s specific goals. When it comes to Drupal design, context is everything. Make sure the agency you choose for your project takes the time to understand the environment in which you operate rather than just churning out websites factory style.
Steer clear of agencies that don't mention accessibility
If a proposal from a web design agency doesn’t mention how they’re addressing web accessibility or usability, you should consider this a red flag. Following accessibility standards in design and development allows users with disabilities, such as visual impairment or limited mobility, to access your content—and helps everyone find the information they’re looking for. Depending on your website’s domain, it may even be legally required that your website meet WCAG criteria. When it comes to accessibility, there are no shortcuts.
Conclusion
Keep these tips in mind when you’re ready to find the right Drupal agency for you and your website. To learn more about user-centered web design for Drupal websites, visit our blog or contact us to see how Redfin can help!
Migrate Drupal WYSIWYG to Paragraphs

In November 2022, the Drupal community and the Drupal Security Team will end their support for Drupal 7. By that time, all Drupal websites will need to be on Drupal 9 to continue receiving updates and security fixes from the community. The jump from Drupal 7 to 9 is a tricky migration. It often requires complex transformations to move content stuck in old systems into Drupal’s new paradigm. If you are new to Drupal migrations, you can read the official Drupal Migrate API, follow Mauricio Dinarte’s 31 Days of Drupal Migrations starter series, or watch Redfin Solutions’ own Chris Wells give a crash course training session. This blog series covers more advanced topics such as niche migration tools, content restructuring, and various custom code solutions. To catch up, read the previous blog posts Drupal Migration Basic Fields to Entity References and Migration Custom Source Plugin.
So the Drupal 7 website you’ve been tasked with upgrading to Drupal 8 has WYSIWYG fields filled with various images, videos, iframes, and tables all with inconsistent formatting. You want to take advantage of this upgrade by switching to a more structured content editing system like Paragraphs, so all those special cases will have a consistent editor experience and display. There is too much content to do this manually, so you need an automated migration. But to impose all this structure, you need to intelligently divide ambiguous content into your specific destination paragraphs. This is a difficult migration task for a few reasons.
- There are multiple paragraph types, so they can’t share one migration.
- The original WYSIWYG content can be broken into several paragraphs of several of different types, but the Drupal migration API wants one source entity to become one destination entity as discussed in this blog post.
- The destination node needs to reference the paragraphs in the exact order as the original content.
These are tricky situations without a widely agreed upon solution. There are some custom migration modules that could help like Migrate HTML to Paragraphs. However, they may not fit your exact guidelines, especially if your paragraphs are referencing further entities like media or ECK entities. So how do you handle this?
There is no perfect solution. That said, one recipe for success is to write a custom process plugin that breaks up the WYSIWYG content, creates the correct paragraphs on the fly (as well as any file/media/ECK entities), and returns the paragraph IDs in the correct order for the destination node to reference. But beware: these paragraphs can’t be rolled back or updated through the migration pipeline. This makes testing more difficult because running a migration update is no longer idempotent, which means running it multiple times in a row will stuff the database with orphaned paragraphs. This simplifies the whole problem to one custom plugin. Here, the credit belongs to Benji Fisher for the starting point code. Keep in mind there are two shortcomings with this code that we will resolve later on.
Let’s break it all down. The first step is to import the WYSIWYG data into a DOMDocument in order to programmatically analyze the HTML. The DOMDocument is a data tree where each HTML tag is represented as a DOMNode that references any tags inside of it as children. You want to split up this DOMDocument so that each piece of content gets neatly mapped into the best fitting paragraph type. Since most of the content is simple text, the text paragraph type will be the default. So you need to test each piece of content to see if it matches a different paragraph type like image, video, or table. If it doesn’t match any of them, then you can safely drop it into the default text paragraph. You should start this process by iterating through all the top-level DOMNodes. For example:
<div class="wysiwyg-container">
<div class="top-level">
<p class="text"></p>
</div>
<div class="top-level">
<img class="image" />
</div>
<div class="top-level">
<p class="text"></p>
</div>
<div class="top-level">
<table class="table"/>
</div>
</div>
When you start with the wysiwyg-container div, you will see four direct children with the top-level class. Starting with the first child, test for each special case. One of the advantages of using a DOMDocument is that you can use the getElementsByTagName function to ask any DOMNode if it has children tags like img, table, or iframe. On a match, turn all the content in the branch to a new paragraph. Otherwise, put each chunk of consecutive text into a new text paragraph. Here lies the first problem with Benji’s template: branches with mixed content.
Most of the time this isn’t an issue. If there’s a table inside a div, you probably want the entire div for your table paragraph. However, if there’s an image inside an anchor tag, your image paragraph will grab the image data but ignore the link, losing data along the way.
{# Top level tag #}
<div class="top-level">
{# Link around image #}
<a>
{# Image #}
<img />
</a>
</div>
This may be an acceptable loss, or an issue that can be flagged for manual intervention. Otherwise, you’ll need a method that can recursively traverse an entire branch of the DOMDocument, cherry-pick the desired HTML element, and put the rest into the default bucket.
For instance:
/**
* Recursively navigate DOM tree for a specific tag
*
* @param $post
* The full page DOMDocument
* @param $parent
* The parent DOM Node
* @param $tag
* The tag name.
* @param string $content
* The content string to append to
*
* @return []
* Return array of DOM nodes of type $tag
*/
static protected function recursiveTagFinder($post, $parent, $tag, &$current) {
$tagChildren = [];
// Iterate through direct children.
foreach ($parent->childNodes as $child) {
// DOMText objects represent leaves on the DOM tree
// that can't be processed any further.
if (get_class($child) == "DOMText") {
$current .= $post->saveHTML($child);
continue;
}
// If the child has descendents of $tag, recursively find them.
if (!is_null($child->childNodes)
&& $child->getElementsByTagName($tag)->length != 0) {
$tagChildren += static::recursiveTagFinder($post, $child, $tag, $current);
}
// If the child is a desired tag, grab it.
else if ($child->tagName == $tag) {
$tagChildren[] = $child;
}
// Otherwise, convert the child to HTML and add it to the running text.
else {
$current .= $post->saveHTML($child);
}
}
return $tagChildren;
}
If a top level DOMNode indicates that it has an img tag, then this method will search all the DOMNode children to find the img tag and push everything else into the default text paragraph, the $current variable. There will likely be some disjointed effects when pulling an element out of a nested situation: a table may lose special formatting or an image may not be clickable as a link anymore. Some issues can be fixed in the plugin. In the migration, I checked if any img tags had an adjacent div with the caption class and stored that in the caption field on the paragraph. Again, others may need to be manually adjusted, like reordering paragraphs or adjusting a table. Remember that it’s much faster to tweak flagged migration content than to find and fix missing data manually.
On to the next issue, let’s dig into embedded media in Drupal 7. The tricky aspect here is that the media embed is not stored in the database as an image tag, but as a JSON object inside the HTML. This requires a whole new set of tests to parse it out. To start, check each DOMNode for the opening brackets of the object [[{ and the closing brackets }]]. If it only contains one or the other, then there isn’t enough information to do anything. If it contains both, then get the substring from open to close and run json_decode. This will either return an array of data from the JSON object or null if it’s not valid JSON. The data in this array should contain an fid key that corresponds to the file ID of the embedded image. That file ID can then be used to grab the image from the migration database’s file_managed table and create an image paragraph.
Those are the main gaps in Benji Fisher’s custom source plugin. Of course each implementation requires even more tweaks and data manipulations to get the exact migration to work correctly. Some content simply will not transfer cleanly, so remember to test thoroughly and stay in tight communication with your client in order to turn WYSIWYG chaos into neat paragraphs.
If you found this migration series useful, share it with your friends, and don’t forget to tag us @redfinsolutions on Facebook, LinkedIn, and Twitter.
Drupal Migrate Basic Fields to Entity References

In November 2022, the Drupal community and the Drupal Security Team will end their support for Drupal 7. By that time, all Drupal websites will need to be on Drupal 8 to continue receiving updates and security fixes from the community. The jump from Drupal 7 to 8 is a tricky migration. It often requires complex transformations to move content stuck in old systems into Drupal’s new paradigm. If you are new to Drupal migrations, you can read the official Drupal Migrate API, follow Mauricio Dinarte’s 31 Days of Drupal Migrations starter series, or watch Redfin Solutions’ own Chris Wells give a crash course training session. This blog series covers more advanced topics such as niche migration tools, content restructuring, and various custom code solutions. To catch up, read the previous blog posts Custom Migration Cron Job, Migration Custom Source Plugin, and Connecting a Transact SQL Database to Drupal.
Migrating from Drupal 7 to Drupal 8 often requires restructuring your content, like transforming an unlimited text field into paragraphs or a list text field into a taxonomy reference. The tricky part is that the migration pipeline wants each source entity to go to one destination entity, but each paragraph or taxonomy term is a new entity and a single node can reference several of these.
So how do you break up data from one entity and migrate it into multiple entities?
Manual entry
If there’s a small set of old content or you’re already manually adding new content, then manual entry is a viable solution, but it shouldn’t be the default for large migrations. Going this route, you want to set up content editors for easy success. If possible, reduce the number of actions needed for a repeated task. With some clever string concatenation in your query results, you can create exact links to all the node edit pages that need updating. This is much easier than giving someone a node id or page title and asking them to fix that page. Just because it’s not an automatic migration, doesn’t mean we can’t automate aspects of it.
CSV Importer
The CSV Importer module is useful for simple data that already exists in a CSV file or can be quickly exported as a CSV file. For example, a spreadsheet with hundreds of country names could easily be imported as taxonomy terms with this tool. Or a list of emails and names could be imported as Users. Once you’ve migrated your data, you can reference them in other migrations using the static_map plugin or a custom process plugin to lookup the correct entity reference. Be careful not to abuse the static_map plugin with hundreds of mappings. In the country example, if the source data contains the name of the country that you want to reference in the destination, you could write a process plugin that gets the taxonomy id from the name. Remember that once entities are migrated you can use the full power of Drupal to find their id’s in later migrations.
Generate entities during migration
Use the entity_generate plugin or a custom plugin to create the entities during the migration process. This gives more control over how the data is transformed, but there’s no way to rollback or update the generated entities through the migration API. This shouldn’t be the default, but can be necessary for more complicated matters such as breaking down a dense wysiwyg field into separate paragraphs (see Benji Fisher’s custom process plugin).
Migrate entities separately with a custom source plugin
See our earlier blog post for a step-by-step guide on this. Drupal core provides lots of useful source plugins, but sometimes you need a custom query to migrate specific source data into entities. This approach gives you that flexibility within Drupal’s migration workflow. Unlike the previous option, you can still rollback and update entities and leverage all the other migration tools.
How you perform a data transformation like this is largely contextual, but these are powerful tools that can be used in many cases. Contact us with any questions regarding complex Drupal migrations, or if you are looking for a Drupal agency to help with your next website project.
Migrating into Layout Builder

This year at DrupalCon North America Redfin Solutions’ CTO Chris Wells had the honor to speak for the first time at a DrupalCon. His presentation Migrating into Layout Builder had the privilege of being one of the most well-attended sessions of the conference.
The Client
Redfin Solutions has a longstanding relationship with the University of New England (UNE)--Maine's largest private university--and they were at a turning point where their previously cutting-edge website felt dated, especially the content editor experience. With Drupal 7's end-of-life on the horizon, we worked with them to come up with an upgrade plan to Drupal 8, so that we would have better access to a modern interface.
Previously, their Drupal website had been implementing responsive component-based design principles using WYSIWYG Templates. With more modern tools like Gutenberg and Layout Builder in core, we knew we had great options and opportunities to provide a better content editor experience.
The Transformation
We knew that we would have to find a strategy for migrating the older paradigm to the new paradigm, and for this we chose layout builder. With its core support and logical application of blocks as components, it was a natural choice. But, how would we get larger blocks of HTML into a place where all new pages were using the new paradigm of pages where each page is a Layout Builder override?
Luckily, Drupal has just such a way to transform data on input, which is the Migrate API. The Migrate API follows a common pattern in Computer Science called Extract, Transform, Load. In the parlance of our times (that is, Drupal), we use the phrases "source" (extract), "process" (transform), and "destination" (load). Each of these phases are represented by Plugins to the Migrate API.
Our Situation
In the case of UNE, we were migrating from (source) Drupal 7 nodes (the page body field) into (destination) "basic text" blocks. For the source, we used the live Drupal 7 database on Pantheon. The "basic text" block is the one that comes out of the box in Drupal 8 as a custom block type, and has a title and a body.
We did NOT go down the rabbit hole of regex'ing out each of the components, but rather we migrated the old body into the new paradigm, so that every page uses the same paradigm from the start, and content editors can expand into using layout builder overrides over time. We simply migrated in some legacy styles, which eventually we will discard. We had the staff and resources to clean up any egregious inaccuracy in the translation as needed, so this ended up being the most time-and-cost-efficient solution.
However, the real magic of this migration is really the process part, where we change the data into the format it needed for layout builder.
Layout Builder Storage
So first, we need to understand how Layout Builder actually stores things behind the scenes. Much like an entity reference field, layout builder is really storing a list of sections. When you build a page with Layout Builder, you are adding sections to it (a one-col, followed by a two-col, followed by another one-col, for example). Much like with regular field tables, it stores the entity ID, revision ID, delta (so it knows the right order!), and then some data value. For taxonomy term references, for example, it would store the "tid" for the term being referenced.
With Layout Builder, there's additional complication. Since each section may contain multiple components, there's an extra layer where we need to then store the components for a section each in their proper order.
For this, Drupal's Layout Builder is not nesting another set of entity references. Instead, it's actually storing a serialized Section object. One of the main tenets of a Section object is an array of SectionComponent objects, which each store their own location and position within the section.
The actual table where this information is stored is the [entity]__layout_builder__layout table in the database. Depending on which entity you've enabled Layout Builder overrides for, this may be the node__layout_builder__layout table, or the user__layout_builder__layout table.
Most layout builder SectionComponents are just "blocks" in the traditional Drupal sense of that entity. With that said, there is one new concept that should be introduced, which is whether or not blocks are to be considered "re-usable." Re-usable blocks are the ones you normally create from Structure > Blocks > Custom Block Library, and you then place to be "re-used" across the website, for example on a sidebar on every page.
Non-re-usable blocks are those which are created when you insert block content into a Layout Builder layout. The difference between these two is really just a boolean (and hidden) field on the block, which helps filter blocks using the UI.
And, the very last piece of the storage puzzle to be aware of is the "inline_block_usage" table. This simply stores the block_content_id, the layout_entity_type (ex.g. "node"), and the layout_entity_id (ex.g. "node id"). It's a record of where the non-re-usable blocks are, in fact, used.
OK, so let's do this!
We need to transform Drupal 7 node bodies into blocks, and then migrate the pages into pages, where the "body" of the node is now the Layout Builder overrides.
To do this, we are going to:
-
migrate bodies into non-re-usable blocks
-
migrate the nodes into nodes
-
be sure and link up the previously migrated blocks as Layout Builder Sections/SectionComponents
To help demonstrate these concepts, I've created a fully-functional website repo on Drupal 9 using some CSVs as a source. I'm going to dissect some of the main parts of that for you.
Step 1: Import the Blocks
In many ways, this is a very standard block migration, but the special thing to call your attention to is the "reusable" field in the "process" section:
# whether or not it's reusable
reusable:
plugin: default_value
default_value: 0
This specifies that the blocks coming in are inline blocks. You may or may not want to use this, but we certainly did, and this is how you set it.
Step 2: Import the Nodes
In many ways, you are just migrating node fields in the way you normally would, mapping fields like title, uid, etc.
Where this one gets special is that we migrate into a field called layout_builder__layout which is the field that stores the overrides. With that, fields expects a Section object (or an array of Sections).
# This is the layout_builder__layout field, which stores everything!
layout_builder__layout:
# Where do we get them from? This `components` field comes from us. We use prepareRow to set it.
source: components
# We need a custom plugin to correctly map this.
plugin: layout_builder_sections_pages
The source for where to get the "body" (blocks / SectionComponents for our Section) is this "components" field. That's not a field in my CSV, it's one where I do a lookup to get all the blocks that were migrated in relative to this node. To do this, I use the prepareRow() method provided by migrate_tools to add a new source property.
# Basics about the source plugin - where to get the data,
# what kind it is, describe the columns in the csv.
source:
plugin: my_pages
In this new prepareRow method, we can look up the migrated blocks and return them in the correct order; each will become a section component:
Now, the components source field is an array of (non-re-usable) block IDs.
Now, we can use that with our custom plugin which is a Migrate API Process Plugin.
Where the Magic Happens
The process plugin has a main entry point of transform(). This method is responsible for returning a value formatted in the way that the destination plugin expects it. In our case, we need to return a Section (or perhaps an array of Sections if you're feeling adventurous). Remember that SectionsComponents primarily make up Sections, we need to first build up the SectionComponents themselves.
To do this, we need access to the UUID generator service in Drupal, and to create a configuration array for the SectionComponent. The following array details the configuration.
-
id: the plugin and derivative you're using, specifically for us "inline_block" and then the bundle, yielding "inline_block:basic" (the type of block).
-
label: what the label of this block is (the block title). This is a required field, so set it to something.
-
provider: layout_builder - always the same in our case.
-
label_display: whether or not to show the label (boolean)
-
view_mode: which view mode to use when displaying this block
-
block_revision_id: the revision ID of the block to display
-
block_serialized: the serialized version of the block (you can probably leave this null and it will be serialized for you later)
-
context_mapping: to be perfectly honest I don't know what this is and maybe someone out there can explain it to me, but it works when it's an empty array :)
After creating your SectionComponents array, you can return a new Section object by specifying the layout you're using for that section, any settings for the Section, and the array of SectionComponents to put into it.
Try it for Yourself!
If you download the example repo, you can restore the included DDEV database snapshot (if using DDEV) or use the .sql file to import the database. You may need to change the paths in your migrations depending on your setup.
As always feel free to be in touch if you would like to learn more!
Connecting a Transact SQL Database to Drupal

In November 2022, the Drupal community and the Drupal Security Team will end their support for Drupal 7. By that time, all Drupal websites will need to be on Drupal 8 to continue receiving updates and security fixes from the community. The jump from Drupal 7 to 8 is a tricky migration. It often requires complex transformations to move content stuck in old systems into Drupal’s new paradigm. If you are new to Drupal migrations, you can read the official Drupal Migrate API, follow Mauricio Dinarte’s 31 Days of Drupal Migrations starter series, or watch Redfin Solutions’ own Chris Wells give a crash course training session. This blog series covers more advanced topics such as niche migration tools, content restructuring, and various custom code solutions. To catch up, read the previous blog posts Custom Migration Cron Job and Migration Custom Source Plugin.
This blog uses the 8.x version of the sqlsrv module. For Drupal 9+ implementations follow updated documentation from the module.
Most often in Drupal 8, your migration source will be a CSV file, JSON file, or another Drupal database. In some cases your Drupal website needs to coexist in a larger infrastructure. Thankfully, there are various modules for synchronizing Drupal with tools like Salesforce, Bynder, and GatherContent. However, not everything is as clean as those user-friendly modules. This article will dig into migrating data from a Microsoft server using Transact-SQL into a standard Drupal 8 website.
As with any database in Drupal, it starts in the settings.php file. The basic setup for a Transact-SQL database looks like this:
$databases['YOUR_DATABASE_NAME']['default'] = array (
'database' => '',
'username' => '',
'password' => '',
'prefix' => '',
'host' => '',
'port' => '',
'namespace' => 'Drupal\\Driver\\Database\\sqlsrv',
'driver' => 'sqlsrv',
);
“YOUR_DATABASE_NAME” is the key Drupal will use to reference this database, but it does not need to match the actual database name. The other credentials such as database, username, password, prefix, host, and port, need to be filled out based on your specific setup and server, but the last two keys are more general and refer to the type of database.
By default, Drupal uses a MySQL database, so the “driver” field is typically set to “mysql.” However, Drupal by itself does not know how to communicate with a Transact-SQL database, so just setting the “driver” to “sqlsrv” will throw an error
To provide that support, first install and enable the SQL Server module (sqlsrv). But the “drivers” folder in the SQL Server module needs to be accessed at the Drupal root folder (usually called “web” or “docroot”). There are two ways to do this:
- Manually copy the “drivers” folder from the SQL Server module (modules/contrib/sqlsrv/drivers) into the Drupal root folder.
- Create a symbolic link (symlink) to the “drivers” folder from the Drupal root folder with a command like this “ln -s modules/contrib/sqlsrv/drivers/ drivers”. The symlink allows the module to update without manual adjustments.
With the proper credentials and connections, Drupal will now be able to read from the Transact-SQL database.
Now the actual migration can be written. There is no core migration source plugin for this, so you will need to write a custom source plugin that extends DrupalSqlBase. Use Drupal’s dynamic query API to get the database's data, ensuring at least one field can be used as a unique identifier for each row. Once the source plugin is written, the rest of the migration will work as usual.
Migration Custom Source Plugin

In November 2022 the Drupal community and the Drupal Security Team will end their support for Drupal 7. By that time, all Drupal websites will need to be on Drupal 8 to continue receiving updates and security fixes from the community. The jump from Drupal 7 to 8 is a tricky migration, often requiring complex data transformations to fit legacy content into Drupal’s new paradigm. If you are new to Drupal migrations, you can read the official Drupal Migrate API, follow Mauricio Dinarte’s 31 Days of Drupal Migrations starter series, or watch Redfin Solutions’ own Chris Wells give a crash course training session. This blog series will cover more advanced topics such as niche migration tools, content restructuring, and various custom code solutions. See the first blog in the series Custom Migration Cron Job.
There are lots of tools built into Drupal 8 (D8) and Drupal 9 (D9) to assist with migrating from a Drupal 7 (D7) website. There is a whole suite of source and destination plugins that allow you to take data from any D7 node, file or user and migrate it into whatever D8 or D9 entity you want. But Drupal can’t account for every single data source you might have, so at some point in your migration you may hit a snag and need to write your own custom migration source plugin. Luckily, Drupal makes this straightforward.
If you don’t already have a custom migration module built, you can follow Mauricio Dinarte’s tutorial. Once you have that set up, go to your custom migration module and create the following nested folder structure for your custom source plugin:
your_custom_module/
├─ src/
│ ├─ Plugin/
│ │ ├─ migrate/
│ │ │ ├─ source/
│ │ │ │ ├─ CustomSourcePlugin.php
Then create a new PHP file in the source folder.
Now we can write our plugin. If you’ve never written a source plugin before, you can use the <a href="https://api.drupal.org/api/drupal/core%21modules%21node%21src%21Plugin%21migrate%21source%21d7%21Node.php/8.9.x">d7_node</a> source plugin for reference (this is the Drupal core source plugin for migrating nodes from a Drupal 7 database). Set up your namespace and underneath it add use Drupal\migrate_drupal\Plugin\migrate\source\DrupalSqlBase;. Then create a class that extends DrupalSqlBase with an @MigrateSource definition commented above it like so:
<?php
namespace Drupal\your_module\Plugin\migrate\source;
use Drupal\migrate_drupal\Plugin\migrate\source\DrupalSqlBase;
/**
*
* @MigrateSource(
* id = "custom_source_plugin",
* )
*/
class CustomSourcePlugin extends DrupalSqlBase {
Note that your class name should be in CamelCase as usual, but the ID should be in snake_case. The ID is how you will reference your source plugin in a migration YAML file.
Inside your custom source plugin, you will need to create four public functions: public function query(), public function initializeIterator(), public function fields(), and public function getIds().
<br/>
<br/>
<strong>public function query()</strong>
Use this to query your source database (such as an old D7 website or whatever external database you are pulling data from). You will build your query using Drupal’s <a href="https://www.drupal.org/docs/8/api/database-api/dynamic-queries">Dynamic Query API</a>. In this example, I have a D7 website that uses an unlimited text field called field_footnote to add footnotes to a node. But in the new D8 website, I want each footnote to be its own entity, while making sure they each stay in the correct order on the correct page. This means I need to process footnotes one by one even though a single node can have several. I also need each footnote to know which node it came from and its order on the page, so the footnotes don’t get scrambled.
To handle this, the query is grabbing the “footnote” text field off all the nodes in the Drupal 7 source database with the entity_id, delta, and field_footnote_value fields selected:
$query = $this->select('field_data_field_footnote', 'f')->fields('f', [
'entity_id',
'delta',
'field_footnote_value',
]);
$query->condition('entity_type', 'node', '=');
return $query;
This means that I process my old Drupal 7 field_data_field_footnote table row by row, turning each footnote into its own entity while keeping track of its parent (entity_id), order (delta) and value (field_footnote_value). This can be the trickiest step to get right because the whole source plugin depends on how the data is queried here.
<br/>
<br/>
<strong>public function initializeIterator()</strong>
<br/>
The initializeIterator function is necessary to run the query and start the iterator. All you need is:
$results = $this->query()->execute();
$results->setFetchMode(\PDO::FETCH_ASSOC);
return new \IteratorIterator($results);
If you need to set any constants for the migration, you can do that at this point as well: see <a href="https://api.drupal.org/api/drupal/core%21modules%21file%21src%21Plugin%21migrate%21source%21d7%21File.php/8.9.x">d7_file</a>. <br/> <br/>
<strong>public function fields()</strong>
<br/>
The fields function lets you state the queried fields from the source table and provide labels:
return [
'entity_id' => $this->t('Entity ID'),
'delta' => $this->t('Delta'),
'field_footnote_value' => $this->t('Footnote'),
];
<strong>public function getIds()</strong>
<br/>
In the getIds function, you define which data field or fields will be used as unique identifiers. In my footnote example, multiple footnotes can be on the same node, so I need more than just the node ID to uniquely identify them. I also need to add the delta (the footnote’s order on the node).
return [
'entity_id' => [
'type' => 'integer',
],
'delta' => [
'type' => 'integer',
],
];
The entity_id and delta fields will get translated as sourceid1 and sourceid2 respectively in the migrate_map table. <br/> <br/>
That’s all you need to create your custom source plugin. Now you can write a migration to use it. Remember that in your migration YAML file you will use the @MigrateSource ID that you set in the comment above the class, not the class name.
If you want some extra credit, you can add a fifth public function, prepareRow. This allows you to make data manipulations on each row before it gets sent to the rest of the migration. If I wanted to set a character limit on my footnotes I could use prepareRow to trim or flag any footnotes that are too long. This can also be done as a hook in your module file, hook_migrate_prepare_row.
Custom Migration Cron Job

In November 2022 the Drupal community and the Drupal Security Team will end their support for Drupal 7. By that time, all Drupal websites will need to be on Drupal 8 to continue receiving updates and security fixes from the community. The jump from Drupal 7 to 8 is a tricky migration, often requiring complex data transformations to fit legacy content into Drupal’s new paradigm. If you are new to Drupal migrations, you can read the official Drupal Migrate API, follow Mauricio Dinarte’s 31 Days of Drupal Migrations starter series, or watch Redfin Solutions’ own Chris Wells give a crash course training session. This blog series will cover more advanced topics such as niche migration tools, content restructuring, and various custom code solutions.
There’s a certain leniency afforded to migrating content from an old Drupal 7 website to its new Drupal 8 rebuild. Preserving old content with all its outliers can be complicated and tedious. However, it is typically run only once in production then augmented and completed. Take notes for future migrations and move on. This leniency is not available for ongoing migrations that need to be run routinely to keep a website’s content up to date. This can be anything from a website's directory to up-to-the-minute news and events data where the data comes from outside the website and requires a custom migration. Here the code needs to work consistently and report errors gracefully.
To run these migrations on cron, there are a few different options. The easiest is to use a module like Migrate Cron Scheduler or Migrate Cron. Both of these allow you to quickly pick a custom migration to run on cron and choose its frequency. Migrate Cron Scheduler, however, allows the user to configure the “update” and “sync” flags on the migration import.
The "update" flag will update all previously imported entities. The "sync" flag will also remove any previously imported entities that are no longer in the source database, so that the source and destination are synchronized.
These modules also let you choose a migration group, so that the migration import will automatically respect migration dependencies. The downside is that any custom code that needs to be run in conjunction with the migration will have to be split into a different cron job, and there is no setting on these modules to run the migration at a certain time of day or at an irregular frequency.
For situations that require these additional features, install and configure the Ultimate Cron module. This is a powerful tool that can be used to fine-tune any cron job to an exact time and frequency. The combination of Ultimate Cron and a migration cron module will cover the majority of use-cases. However, if custom code or reporting is necessary immediately before or after the migration runs, then a custom cron job may be needed. To build this, go to your custom migration module and create a hook_cron function in the .module file. This file will need to use the following classes:
use Drupal\migrate_tools\MigrateExecutable;
use Drupal\migrate\MigrateMessage;
use Drupal\migrate\Plugin\MigrationInterface;
Exactly how you configure this hook will depend on your situation. For each migration that you want to run on this cron job, you will need to follow these steps. First create an instance of the migration plugin by feeding the migration’s id into the Drupal plugin manager:
$migration = \Drupal::service('plugin.manager.migration')->createInstance($migration_id);
Next, check the status of the migration. Often if there is an error, the migration will be hung in the “importing” state. Running a migration with the “importing” status will result in an error. To get around this, check the status and if necessary reset it to idle:
// Reset migration status.
if ($migration->getStatus() !== MigrationInterface::STATUS_IDLE) {
$migration->setStatus(MigrationInterface::STATUS_IDLE);
}
At this point there are a couple options. You can leave the migration as-is and run a straight import where the content that has already been migrated will remain the same and any new content will be imported. Or set the “update” flag so that new content will be imported and existing content will be updated to match the source: $migration->getIdMap()->prepareUpdate();
Additionally, you can set the “sync” flag to remove any migrated content that no longer exists in the source database (e.g. an event that was cancelled). Note that this option requires at least migrate_tools version 5.
$migration->set('syncSource', TRUE);
Finally, create the MigrationExecutable plugin and run the migration:
$executable = new MigrateExecutable($migration, new MigrateMessage());
$status = $executable->import();
The “status” variable indicates whether the migration ran into any errors. If the status is empty, then there was an error and we can send a report and make custom adjustments to help the migration fail gracefully. Otherwise the migration ran fine.
Once the cron hook is ready, go to the Ultimate Cron jobs page (/admin/config/system/cron/jobs) and click the “Discover jobs” button. Your custom cron job should show up in the table, and you can click the “edit” button to fine-tune the exact timing. For updating or syncing migrations with hundreds of entities, the page may timeout if you manually hit the “run” button for your custom cron job. However, Ultimate cron version 2.x adds the drush commands cron-list and cron-run. Use cron-list to find your cron job id. Then use cron-run with that id and the “--force” flag to manually run your cron job for testing.
The Migrate Cron Scheduler or Migrate Cron module route is much faster to set up and is the better choice for quick, simple migrations that need to be run on the hour. However, for bigger, more complicated migrations that require additional code either immediately before or after the migration, or need to be run in the middle of the night, the Ultimate Cron module combined with a custom cron job provides the most customization and flexibility.
Design for Better Communication with Developers

As a designer and front-end developer, the infamous designer-developer handoff has often been between me and myself. Having spent a lot of time in both roles, as well as having worked closely with other designers and developers, I’ve learned a few practices that help me to answer developer questions right from the start.
Responsive Design
The first question to think about in the visual design stage is how a design will translate from a static idea to something people will use. In the real world, people are using all kinds of devices to interact with a website. There are a number of different use cases to think about here. For example, mobile users may be accessing a webpage without internet access, making an autoplaying video a concern for data usage. However, the most common and notable case to think about here is simply different screen sizes.
It’s pretty common to see mobile, tablet, and desktop designs handed off to a developer. If done well, these are generally enough for defining most of a website. Developers usually are working from 320px up, so it’s important to create mobile mockups at this size. From there we widen the browser to make sure the website still looks correct at the sizes in between what was provided in the mockups. The design for the mobile will be applied all the way up to one pixel below tablet size, and the tablet design will be applied up to one pixel below desktop (you may want to specify this for your developer).
For the most part, we want a consistent experience for each of these devices. If, for example, a user opens the website on an external monitor instead of their laptop, it shouldn’t look like a different website. That said, with some layouts the right breakpoint (browser width at which a component changes) is not right at one of the defined device sizes. As you’re designing, check if any of your components or page layouts need to switch at a more specific browser width. A good test of this is to create an artboard that’s a tiny bit smaller than tablet, and put everything in the mobile layout at that width. If anything looks off, consider defining a different breakpoint for that particular component.
Another case to consider is when the website gets extra wide. The last thing you want is to present the final website to your stakeholders and find the components in disarray on a big TV. Generally I’ll define up to two widths for this. One is the content maximum width, and the other is the website maximum width.
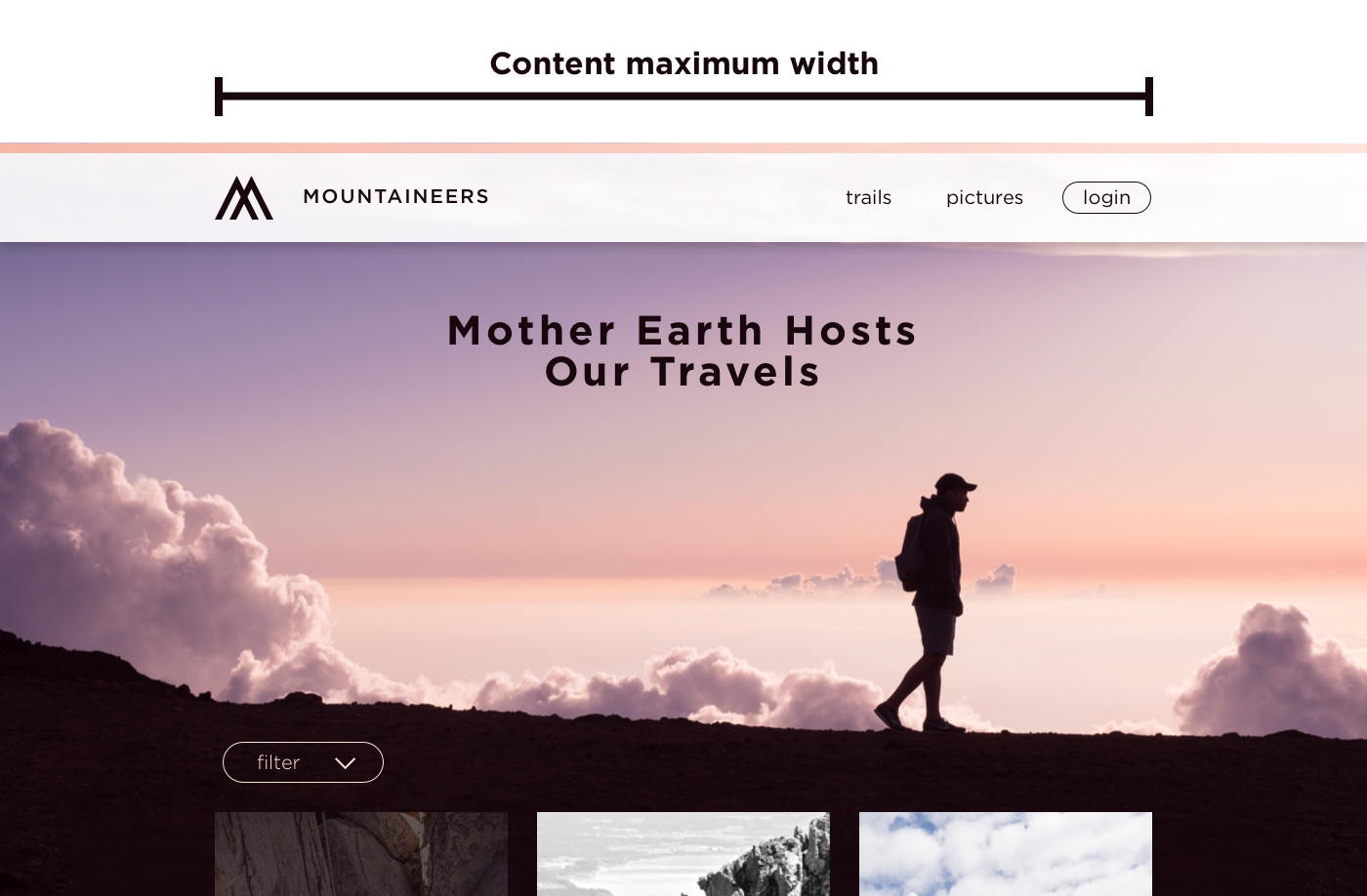
The content maximum width is the size at which the components (such as text or an image) on the website stop increasing in width but the backgrounds (such as a background color or image) keep going. If your content maximum width is particularly large, keep in mind how all your components look stretched to that width. For readability and accessibility of any text on the website, remember that optimal line length is 45-75 characters.
This width may be all you need, but you can also define a website maximum width if you want something like an image background or full width slideshow to stop growing at a wider point. This may just apply to those full width components that are using images, or (less common in modern design) to the whole website. When deciding on whether or not full width components should keep stretching infinitely wide, think about how you want images to look on very large screens. Unless it’s a background image that is matching the height of that component, the wider an image gets, the more vertical space it will take. Also consider if you want large images to look clear at very large sizes or load quickly at normal and smaller sizes. Limiting the width an image component can reach is one way to strike a balance.
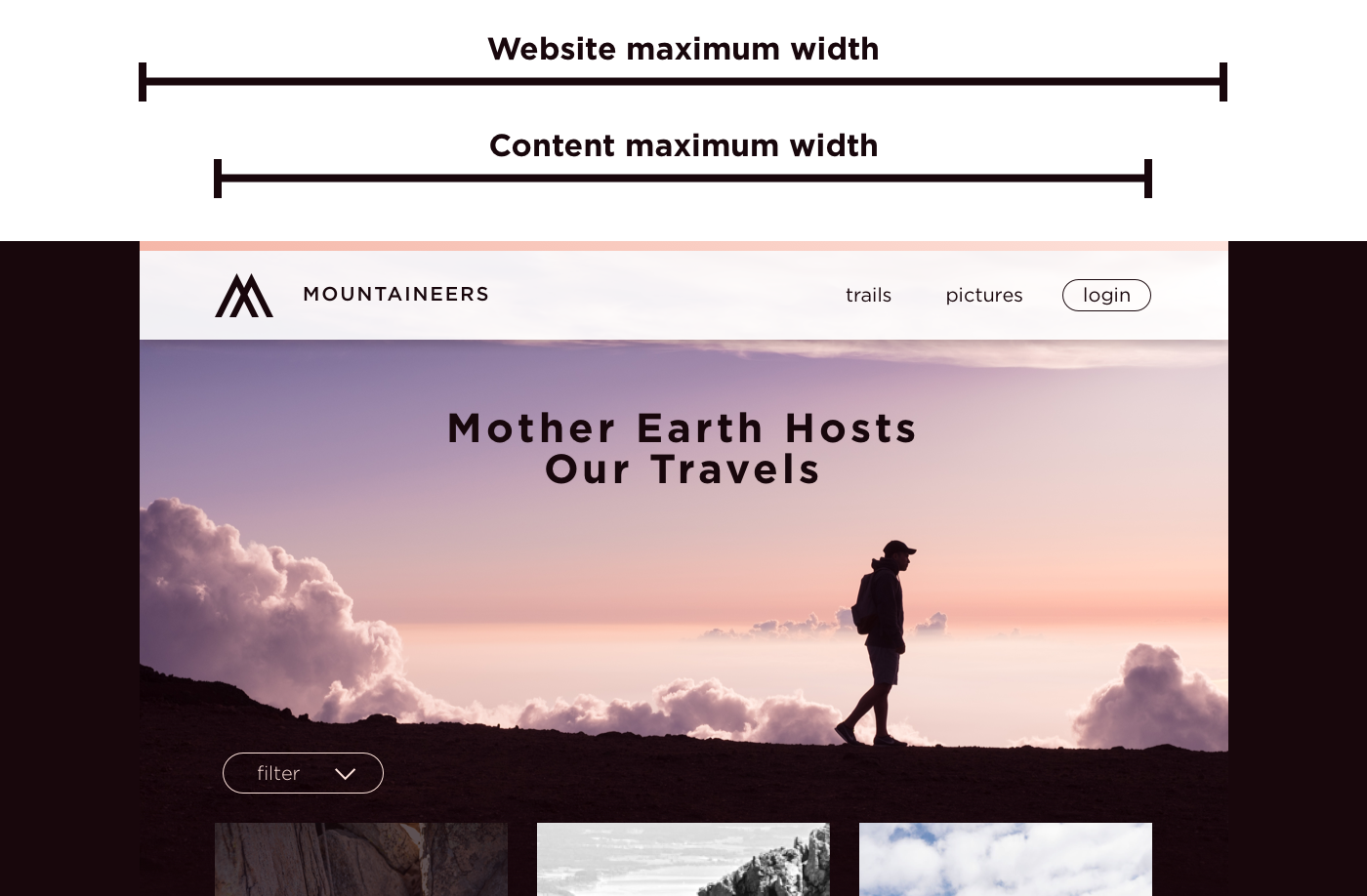
One last thing to define is the padding on the sides between tablet and desktop. When the width gets close to your content maximum width, how much padding stays on the sides as the content begins to shrink? I usually leave 16px between mobile and tablet, and 32px between tablet and the content maximum width (technically the content maximum width plus 64px so I don’t lose the padding too early).
Other common responsive considerations are typography and hover states. For typography, you’ll likely want to define heading sizes for mobile, tablet, and desktop. Also pay attention to line height, as well as spacing above and below a heading. For hover states, just remember that a mobile or tablet user can’t hover, so make sure none of the functionality is lost because of this.
Other tips
This covers most of the important points to keep in mind, but here are a few others:
Try to use a consistent base for sizing, preferably based on the body text size. I usually make my base font size 16px and then try to make typography and spacing stick with multiples of 4px.
Never type with caps lock. Always type in lower or sentence case and use your design software to transform the text to uppercase. This will help if you need to change that style without having to retype, and it allows developers (depending on your method of sharing designs) to copy and paste your text rather than retyping it. It also can be a good reminder to the developer that they should be using css to make text uppercase for accessibility (screen readers read text typed in all caps one letter at a time).
Make sure your images and text are flexible. If you have an image that perfectly lines up with the text overlaying it, be aware of how that component might be used and if the content editors will be changing the image or text. Similarly, be aware of the amount of text a content editor might add to any component. Character counts can always be limited, but it won’t hurt to supply that or show how the component should respond to having more text, especially if that text area is highly dependent on browser width.

One thing that can be easily overlooked is hover and focus states for any interactive elements of your website. For a website to be accessible, it has to be navigable with a keyboard. Focus states are what you see if you tab through a page, and if the difference isn’t notable it will be difficult to do this. Often, hover and focus states can be the same, but there may be some cases where you want to separate them. A form, for example, is an important place to have focus states defined, but you may not need hover states to work the same. Focus states that aren’t specified will generally be automatically provided by the browser, resulting in different appearances between browsers.
One last thing to establish while working with developers is a shared language. A paragraph or a block may mean something different to you as a designer then to a developer working in a content management system. Work together to make sure you have a common understanding of what some of these terms mean. A design system, or even a component library, is a great way to document this. We usually use Invision DSM to share a design system between designers and developers.
Summary
To review, remember the following things as you’re designing:
- Design mobile at 320px
- Define a content and website maximum width
- Create font styles for mobile, tablet, and desktop
- Use a consistent base for sizing, based on your body text size
- Get in the habit of using your UI to transform your text to uppercase
- Make images and text flexible whenever possible, and show components with varying amounts of content
- Provide hover and focus states
- Establish a shared language
When working with developers, it’s important to keep in mind the gaps between design and development when creating a website. While small design details may be obvious to you, a developer may be less aware of pixel distances and small color variations, focused instead on building the website in the best way possible. Ideally, design handoff is not one moment in a months long process, but a continual collaboration. Getting developer feedback while in the design process can save you from wasting time going down an unfeasible pathway, and getting across clear design patterns can ensure a developer makes the right assumptions from the beginning. Understanding a little of each other’s world can help make the whole process a lot smoother.
Writing Accessible Content in a Content Management System

Accessibility isn’t just a concern for web developers. With content being dynamically created, there are a few points content editors can keep in mind to make sure their content is accessible to everyone. Following accessibility standards helps non-visual users, but can also help all users find and understand the information they’re looking for.
Creating Emphasis
One of the most common times accessibility issues pop up is when content editors are trying to emphasize sections of text. It is important to keep in mind that screen readers do not recognize details like different colors or bolded text, but will intonate exclamation points. If it is vital to the understanding of the content that a certain sentence be highlighted, consider using an exclamation point. If it is not vital but may help visual users to better understand the message, your best bet is making use of bold.
From a usability standpoint, be wary of using color for emphasis. Colors can have unintended implications, such as causing the user to think the text is a warning, or even a link. Text also has to pass a certain color contrast ratio with its background to maintain accessibility, so unless a designer or developer with a knowledge of accessibility has picked out new colors for you, it’s best not to introduce more.
Another common mistake when emphasizing content is using all uppercase letters. A screen reader will read this out like an acronym, which could be particularly painful for a full sentence. Aside from screen readers, it is also shown to be less readable for all users when there are more than one or two words in a row in all-caps. Sometimes you’ll see all-caps used on buttons or labels, but the crucial difference is that these are (or should be) made into all-caps with code. A screen reader will usually ignore the css and see the text as it is originally written.
Is bold not enough variation for your content? Talk to your designer or developer about coming up with additional text styles for you to use. You may think to yourself, “I already have a dropdown with five different text styles I can use!” What you’re probably referring to is the heading selector.
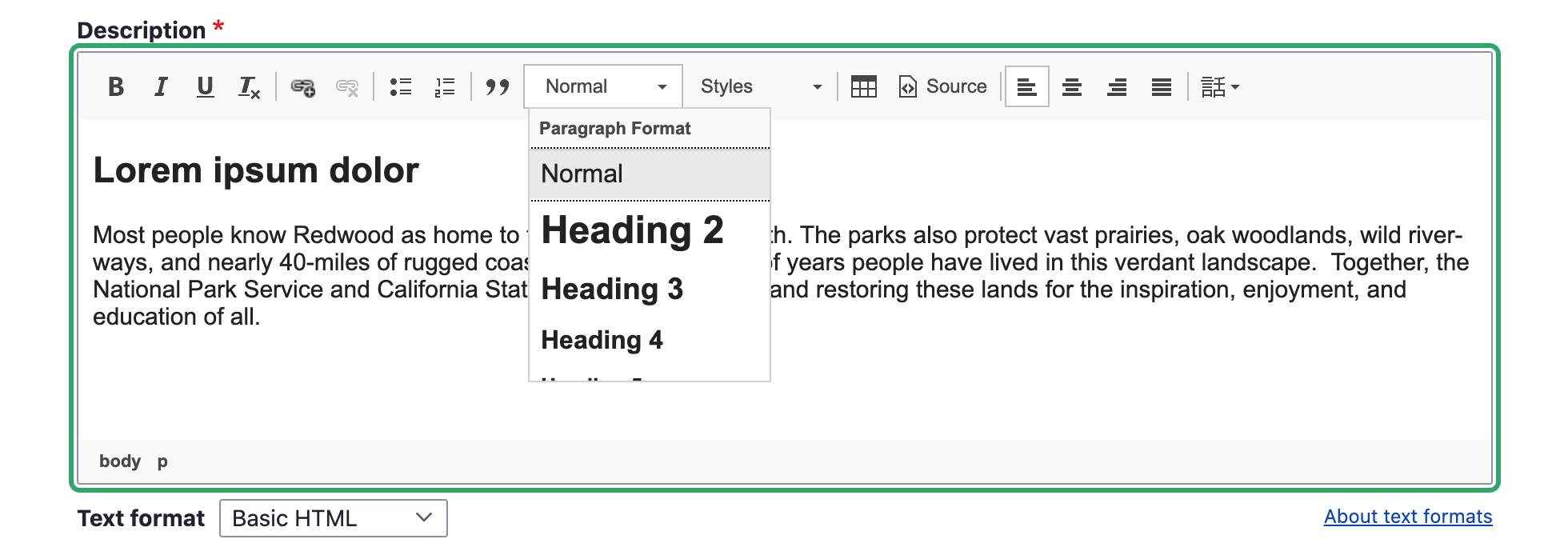
Headings should never be used for emphasis or a stylistic choice. They are a tool to add structure to a page.
Heading Structure
Headings are pieces of HTML that are used to give structure to a page. They make it possible for non-visual users to navigate and understand a page without needing to see visual indicators. There is a specific way headings need to be arranged on a page.
Headings are nested, just like you would see in an outline of a paper where subsections are indented and have a different bullet point or character. Heading 1 is the topmost level, functioning as the title of the page. There should only ever be one H1 on a page, and if you’re using Drupal or any other content management system, the H1 is probably already generated for you as the page title. If you’re working in a body field, for example, you’ll most likely start with H2 to title a section of content. Anything else at this same section level will also be an H2. If you need to label sections within this section, you can start to use H3’s. If you need to go any deeper than this, you can start to use H4’s, H5’s, and H6’s, but if you are going this deep into the structure, it may become difficult to follow for your average user. Here’s an example of heading structure:
(H1) The Most Amazing Chocolate Cake
(H2) My Grandmother’s History
(H2) Ingredients
(H3) Types of flour you can use
(H3) Alternative ingredients
(H4) Vegan alternatives
(H4) Gluten free alternatives
(H2) Instructions
(H3) The cake
(H3) The frosting
An important thing to watch out for is that heading levels don’t skip. You don’t want to go from an H2 right to an H4. That makes it more difficult for non-visual users to understand the structure of the page, and creates inconsistencies for all users. If you keep finding yourself tempted to do this for visual reasons, think about why it feels like the heading style available doesn’t fit, and work with your designer to figure out how best to fix it.
As mentioned before, don’t use headings simply to emphasize text. If you’re making a whole sentence into a heading, it’s probably not the right use. Headings are also not designed to be used for long sections of text. Bigger and bolder does not always mean easier to read. Sometimes a pull quote or a custom text style is an option that will accomplish what you’re looking for, without creating accessibility and usability issues, as well as design inconsistencies between different content editors.
Foreign Languages
Sometimes on your site you’ll need to add text in a different language. Visual users can identify when they won’t be able to read something, but screen readers need a hint that a sentence is in a different language. There’s a simple way to add this hint to your text: the language button. When you add content to a text field, usually you will have a toolbar at the top that allows you to make things bold, add a link, etc. One button that you may see if you’re using Drupal looks like this:
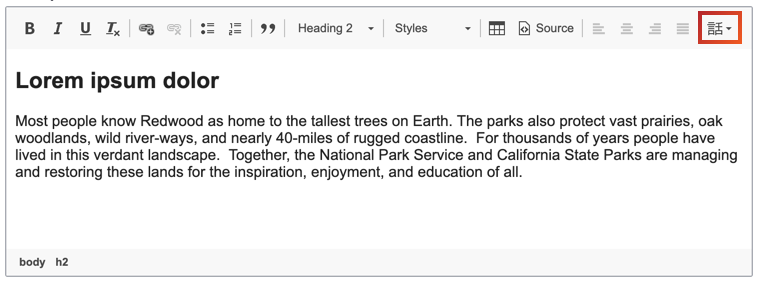
If you see this button, you can highlight your text and select from the dropdown. If you don’t see this button, or any buttons, ask your developer to make it available for that field.
Another thing to note with foreign languages is that users can use external tools to translate the content into a language they understand. For this reason, it is best to stay away from made up words that would only make sense in the language you’re writing, but not others (i.e. “hangry”).
Special Characters
One more content writing trend to avoid is replacing letters with characters, for example “$ave ₵ash” or “see u l8r.” This causes predictable issues for translation and screen readers, but it also can show up incorrectly for anyone. If you have an article titled “$ave ₵ash” it will show up in the url as something like this: yoursite.com/news/ave-ash, which could lead to some confusion when sharing links. The “u” in “see u l8r” would most likely be understood by a non-visual user, but would be impossible to translate.
Writing Accessible Links
Writing good link titles is important, and once you understand how non-visual users navigate a page, it’s easier to accomplish. These links could be inline links, such as a word in a sentence, or could stand alone, such as a button. Regardless, what you want is for link titles to be able to stand on their own. This is because one navigational tool that assistive technology provides users with is a list of links that appear on the page. Imagine a list of links that says “click here,” “learn more,” and “download.” These links don’t give the user any context or information about where the links will go. Instead, create links with text that gives users an understanding of what exactly that link will be doing. No user wants to waste time clicking on a link gives them an unexpected result.
W3.org gives these as examples of successful links (URI refers to the link destination):
A link contains text that gives a description of the information at that URI
A page contains the sentence "There was much bloodshed during the Medieval period of history." Where "Medieval period of history" is a link.
A link is preceded by a text description of the information at that URI
A page contains the sentence "Learn more about the Government of Ireland's Commission on Electronic Voting at Go Vote!" where "Go Vote!" is a link.
Meaningful link text also helps users tabbing through a page from link to link. Users can more easily navigate and determine where to go next without spending more time than wanted on an intermediary page.
Learn more about link accessibility at w3.org.
Writing Good Alternative (Alt) Text
Images that you add to your page need good alt text. When using a content management system, you’ll see a field show up when you add an image, asking for alt text. Alt text allows non-visual users to get the same basic information that the image is giving to a visual user. It is what shows if an image doesn’t load, whether because of a broken image link(?) or a user’s limited internet access. It also provides information to search engines.
Writing good alt text can feel a bit tricky at first. What you want is for your alt text to communicate the content and function of the image. Think of alt text as what you would want to appear in the place of the image if you couldn’t use it. You’ll want to be succinct in describing the image, and avoid any redundancy with the text around it. Screen readers will know that it’s an image, so don’t add text like “image of…” Think about what information is and isn’t helpful, and why you’re adding an image in the first place. Is it just to take up space next to text, or is there something important being conveyed through that image? An image of students on a quad conveys information about student life at the university, whereas a cartoon image of a backpack likely doesn’t add any information.
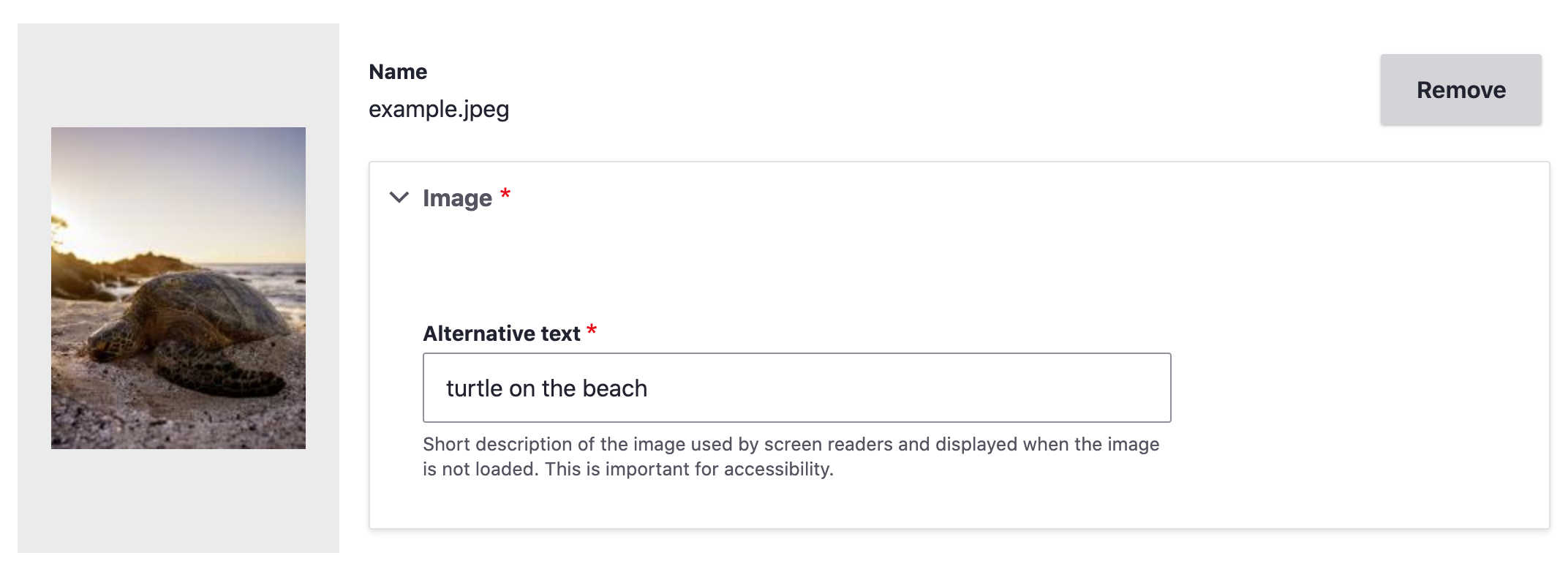
Sometimes the alt attribute of an image should be empty. The alt attribute is the piece of HTML that is holding the alt text you enter when you first add an image. You may instead have a label below your image that is visible to all and acts as alt text. You wouldn’t want a screen reader to read out what would ultimately be the same text twice, so you’ll want an empty alt attribute on the image. The only instance where you want no alt text at all is when an image is only decorative, such as a swirling line between text sections or a generic image added only to break up the text (like the previous backpack example). Alternative text may be a required field when you add an image, in which case adding empty alt text by typing a single space in the field might work for you. If this doesn’t work, you may want to talk to a developer about making alt text optional. Consider how many content editors your site has, and if they all have accessibility training. If it is possible that a lot of images that need alt text could end up without it, it may be best to keep it required and minimize using images that don’t add meaning to a page. If the image has alt text in a caption already and you need to add something into the alt text field to be able to save it, try to add context that isn’t already clear from the caption. In most cases you will want alt text anyway, but ask yourself if the alt text you’re adding will be a help or an unnecessary hindrance to a non-visual user.

When an image is linked, and is the only thing in the link, the alt text needs to describe the function of the link. This is because the link doesn’t have any other text in it, so any clue as to where the link is going to go is taken from the alt text. In this case, you can write alt text as if you were writing link text.
For some great examples of how to write alt text, take a look at the list provided by webaim.org.
Conclusion
Once you understand how different users are experiencing your content, writing with accessibility in mind starts to get easier. It’s not always the most exciting and creative part of writing content, but it can be a rewarding experience to continually remind yourself to think about users that often can be overlooked. Putting yourself in someone else’s shoes can help build empathy and make the web, and particularly your piece of it, a more positive space for all.